Grow It
A full stack plant health monitoring solution utilizing machine learning.

Background:
EarthHack 2020 as the name implies was an environmental-themed hackathon that ended up taking place entirely online after COVID started becoming a serious problem in April. After spending probably too long trying to come up with a great original idea to save the environment, we settled for a plant health monitoring system based on OpenCV.
Machine Learning API:
The project was based around using an OpenCV The API was deployed on AWS Lambda with an API endpoint, which while totally unnecessary for a hackathon, meant that we were fully serverless and could take advantage of cloud scaling. Unfortunately this code is mostly lost to time, so we're stuck with a high level overview.
We started by training an OpenCV model in AWS Sagemaker using labeled data of tomatoes. The model output four confidence
values for binary classification, Healthy_Leaf, Unhealthy Leaf, Healthy_Tomato, and Unhealthy_Tomato.
Most of the work after this point was converting creating AWS lambda layers for the OpenCV and Pandas dependencies.
Once the model was running in AWS lambda it was just a matter of wrapping the code into a REST API.
IoT device:
My main role in this project ended up being connecting everything together and fixing whatever bugs seemed to pop up, the path of least resistance for this was to lump all the extra code into the python running on the IoT device, so I'll go through this code in depth.
First we need to capture an image for processing with the raspberry pi, this is pretty much copied directly from the example code for PiCamera.
# Raspi Stuff (Commented out to run on a non-pi)
from picamera import PiCamera
# Capture image from camera and save to img/temp.jpg
camera = PiCamera()
camera.resolution = (1024, 768)
camera.start_preview() # used for when pi gui is open
sleep(2) # Camera warm-up time
camera.capture('img/plant.jpg')Next we take that image we just saved and base64 encode it so that we can send it over a POST request.
# Context Manager for img files
with open('img/plant.jpg', "rb") as img_file:
base64string = base64.b64encode(img_file.read()) # encode image in base64
file_url = 'img/plant.jpg'We can then construct and send the POST request to our AWS API endpoint.
# endpoint and static header information
url = "https://fu9gq38ul8.execute-api.us-east-2.amazonaws.com/Testing/getprobabilities"
headers = { 'Content-Type': 'application/json' }
# embed base64 encoded image in request body
payload = "{\n \"image\": \"data:image/jpeg;base64," + str(base64string) + "\",\n \"file_url\": \"plant.jpg\"\n}"
# Make POST request
r = requests.request("POST", url, headers=headers, data=payload)The response body I had to pull data from isn't exactly intuitive (remember hackathon with limited team communication),
so it required some cleanup code to extract the useful data.
Example response body:
{"Results": "image classified with following details : probability=0.000001, class=Healthy_Leaf and probability=0.000000, class=Healthy_Tomato and probability=0.999998, class=Unhealthy_Leaf and probability=0.000000, class=Unhealthy_Tomato"}This cleanup code pulls removes everything except the four confidence values and then puts them into the
array decoded_response.
# Handle response
statuses = ["Healthy leaf", "Healthy tomato", "Unhealthy leaf", "Unhealthy tomato"]
response = r.text # extracting response text
response = re.sub('[^0-9]', '', response) # remove all non-numeric
n = 7 # digits per confidence value
decoded_response = [response[i:i + n] for i in range(0, len(response), n)]
print(f'decoded_response: {decoded_response}')All that's left now is to summarise the health of our plant for displaying on the webpage. We take our highest confidence value, ensure that it meets our requirement of majority confidence, and then push that data into a Firebase realtime database.
# Gets max value
highest_val = max(decoded_response)
doc_ref = db.collection(u'plants').document(f'plant{plant_num}')
# Make sure we are confident in highest_val
if float(highest_val) > .5:
highest_name = decoded_response.index(highest_val)
print(statuses[highest_name])
doc_ref.set({
u'status': statuses[highest_name]
})
# Default to undetermined status
else:
doc_ref.set({
u'status': 'Undetermined Status'
})Web Frontend:
The web frontend was a little thrown together and isn't particularly interesting, but here's some screenshots of roughly
what it looked like.
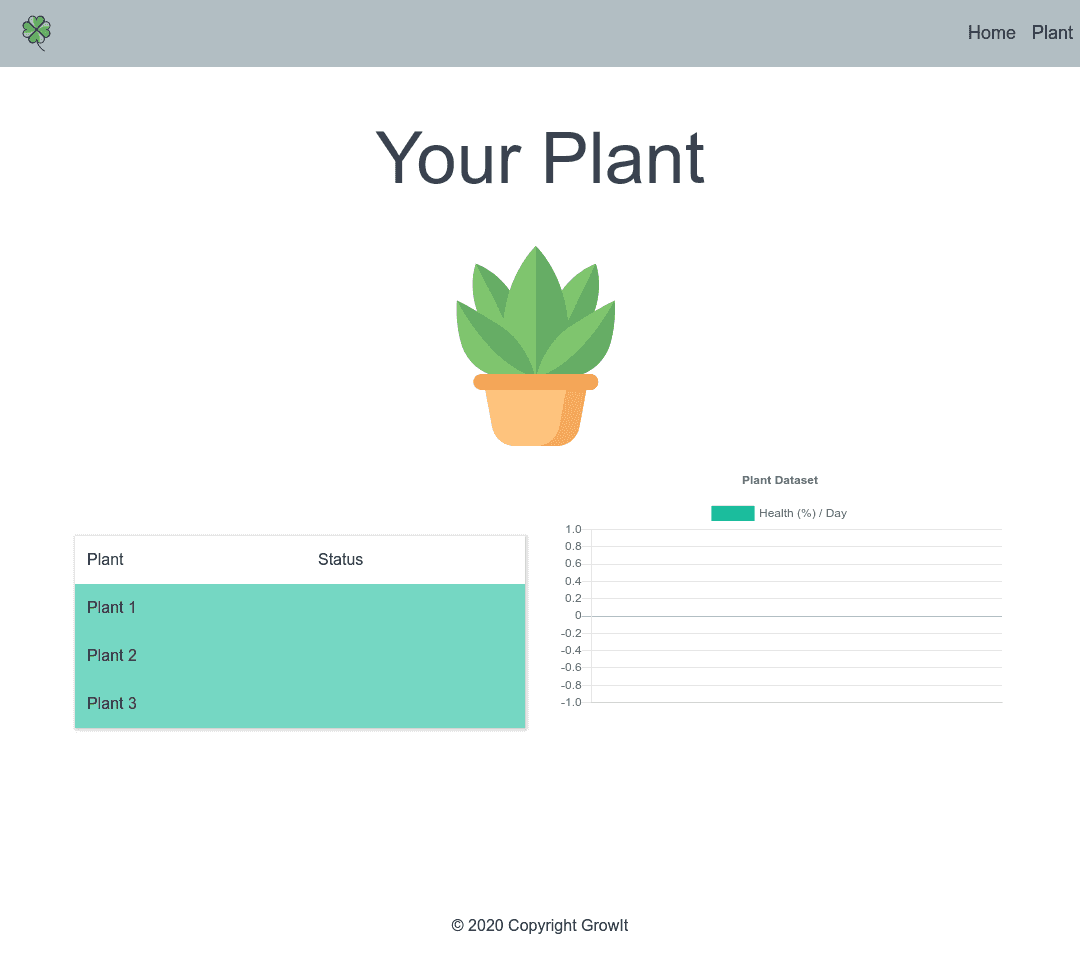
 The data points are missing in the screenshot, but when the database is populated each plant would have a status listed,
and clicking on the plant name would display a graph of plant health over time. This was done by pulling data from our
Firebase realtime database and populating the fields with JQuery and ChartJS.
The data points are missing in the screenshot, but when the database is populated each plant would have a status listed,
and clicking on the plant name would display a graph of plant health over time. This was done by pulling data from our
Firebase realtime database and populating the fields with JQuery and ChartJS.
What I would do differently:
Due to the nature of working remotely with teammates I had never spoken to before the competition, we tried to segment our application as much as possible. This was what led to the ML functionality being its own discreet API in AWS, and meant that there was added complexity in the IoT device. If I were to redo this, instead of sending a response back the IoT device, the API could directly manipulate the database. We could also take this opportunity to move all the cloud functionality to the same provider and eliminate the need for authentication between the database and ML code. AWS even offers Amazon Timestream which is a database optimized specifically for this type of IoT application.